小记录
元组是不可变序列,例如用了*=运算时,会重新创建一个元组并且赋值
原子操作(atomic operation),指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。
python特殊方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from math import hypot
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __abs__(self):
return hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
|
定义一个二维向量类,使用了python的几个特殊方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
'''
如果没有实现
__repr__,当我们在控制台里打印一个向量的实例时,得到的字符串
可能会是 <Vector object at 0x10e100070>。
__repr__ 和 __str__ 的区别在于,后者是在 str() 函数被使用,或
是在用 print 函数打印一个对象的时候才被调用的,并且它返回的字
符串对终端用户更友好。
例如:
>> v * 3
Vector(9, 12)
'''
'''
这两个方法的返回值都是新创建的向量对
象,被操作的两个向量(self 或 other)还是原封不动,代码里只是
读取了它们的值而已。
'''
|
序列构成的数组
1.内置序列类型
容器序列 list、tuple 和 collections.deque 这些序列能存放不同类型的 数据。
扁平序列 str、bytes、bytearray、memoryview 和 array.array,这类 序列只能容纳一种类型。
按照可变和不可变
可变序列 list、bytearray、array.array、collections.deque 和 memoryview。
不可变序列 tuple、str 和 bytes。
第二章 序列组成的数组
2.2 列表推导和生成器表达式
1
2
3
4
|
test = 'abcde'
print ([ord(testvar) for testvar in test])
|
2.4切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
list = [1,2,3,4,5,6]
print(list[2:])
print(list[:2])
s='abcdefgh'
print(s[::2])
'''
[] 运算符里还可以使用以逗号分开的多个索引或者是切片,外部库
NumPy 里就用到了这个特性,二维的 numpy.ndarray 就可以用 a[i,
j] 这种形式来获取,抑或是用 a[m:n, k:l] 的方式来得到二维切片。
'''
list = [0,1,2,3,4,5,6]
list[2:5] = [999,888]
print(list)
|
对序列使用+和*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
'''
。通常 + 号两侧的序列由
相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被
修改,Python 会新建一个包含同样类型数据的序列来作为拼接的结果。
如果想要把一个序列复制几份然后再拼接起来,更快捷的做法是把这个
序列乘以一个整数。同样,这个操作会产生一个新序列:
'''
list = [0,1,2,3,4,5,6]
print(list *2)
print(list +[9,8,7])
board = [['_'] * 3 for i in range(3)]
print(board)
board[1][2] = 'X'
print(board)
'''
如果在 a * n 这个语句中,序列 a 里的元素是对其他可变
对象的引用的话,你就需要格外注意了,因为这个式子的结果可能
会出乎意料。比如,你想用 my_list = [[]] * 3 来初始化一个
由列表组成的列表,但是你得到的列表里包含的 3 个元素其实是 3
个引用,而且这 3 个引用指向的都是同一个列表。这可能不是你想
要的效果。
'''
weird_board = [['_'] * 3] * 3
print(weird_board)
weird_board[1][2] = 'x'
print(weird_board)
|
2.6序列的增量赋值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| '''
+= 背后的特殊方法是 __iadd__ (用于“就地加法”)。但是如果一个类
没有实现这个方法的话,Python 会退一步调用 __add__ 。考虑下面这
个简单的表达式:
a += b
a 实现了 __iadd__ 方法,就会调用这个方法(像 a.extend(b) 一样),如果没有实现的话,首先计算 a +
b,得到一个新的对象,然后赋值给 a
但是*=的效果不一样
'''
list = [1,2,3]
print(id(list),list)
list *=2
print(id(list),list)
tuple1 = (1,2,3)
print(id(tuple1),tuple1)
tuple1 *=2
print(id(tuple1),tuple1)
"""
2418655396032 [1, 2, 3]
2418655396032 [1, 2, 3, 1, 2, 3]
2418657982848 (1, 2, 3)
2418655659776 (1, 2, 3, 1, 2, 3)
可以看到元组进行增量计算时重新创建了对象
"""
|
一个关于+=的谜题
如果对一个元组中的列表使用+=运算

原理
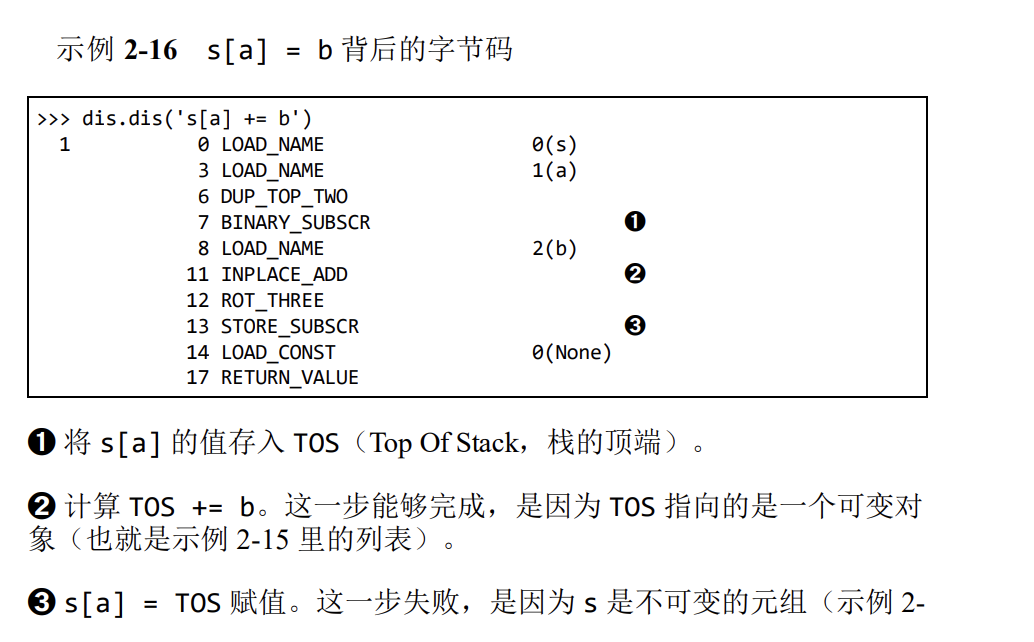
不要把可变对象放在元组里面。
增量赋值不是一个原子操作。我们刚才也看到了,它虽然抛出了异常,但还是完成了操作。
查看 Python 的字节码并不难,而且它对我们了解代码背后的运行机 制很有帮助。
什么是原子操作?
原子操作(atomic operation),指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。
它有点类似数据库中的 事务。
2.7 list.sort方法和内置函数sorted
list.sort 方法会就地排序列表,也就是说不会把原列表复制一份,返回值是 None。
不管是 list.sort 方法还是 sorted 函数,都有两个可选的关键字参数。
reverse 如果被设定为 True,被排序的序列里的元素会以降序输出(也就 是说把最大值当作最小值来排序)。这个参数的默认值是 False。
key 一个只有一个参数的函数,这个函数会被用在序列里的每一个元素 上,所产生的结果将是排序算法依赖的对比关键字。比如说,在对一些 字符串排序时,可以用 key=str.lower 来实现忽略大小写的排序,或 者是用 key=len 进行基于字符串长度的排序。这个参数的默认值是恒 等函数(identity function),也就是默认用元素自己的值来排序。
例子:
1
2
3
4
5
6
7
8
| fruits = ['grape', 'raspberry', 'apple', 'banana']
sorted(fruits)
print(fruits)
print(sorted(fruits))
print( sorted(fruits, reverse=True) )
print(sorted(fruits, key=len, reverse=True))
print(fruits.sort())
print(fruits)
|
2.8 用bisect来管理已排序的序列
书里的解释:
bisect(haystack, needle) 在 haystack(干草垛)里搜索 needle(针)的位置,该位置满足的条件是,把 needle 插入这个位置 之后,haystack 还能保持升序。也就是在说这个函数返回的位置前面 的值,都小于或等于 needle 的值。其中 haystack 必须是一个有序的 序列。你可以先用 bisect(haystack, needle) 查找位置 index,再用 haystack.insert(index, needle) 来插入新值。但你也可用 insort 来一步到位,并且后者的速度更快一些
示例代码:
偷了那里(11条消息) 关于python中‘bisect管理已排序序列’记_runner-liu的博客-CSDN博客的解释,有修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import bisect
import sys
num_hay = [1, 4, 5, 6, 8, 10, 19, 23, 23, 35]
num_need = [0, 1, 2, 5, 8, 10, 14, 20, 23, 38]
row_fmt = '{0:2d} @ {1:2d} {2}{0:<2d}'
'''
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
'''
def demo(bisect_fn):
"""定义测试bisect的函数"""
for needle in reversed(num_need):
position = bisect_fn(num_hay, needle)
offset = position * ' |'
print(row_fmt.format(needle, position, offset))
if __name__ == '__main__':
if sys.argv[-1] == 'left':
bisect_fn_1 = bisect.bisect_left
else:
bisect_fn_1 = bisect.bisect
print('DEMO:', bisect_fn_1.__name__)
print('haystack ->', ' '.join('%2d' % n for n in num_hay))
demo(bisect_fn_1)
|
实际效果:left和right
left是往相同数据的左边插入,right是右边
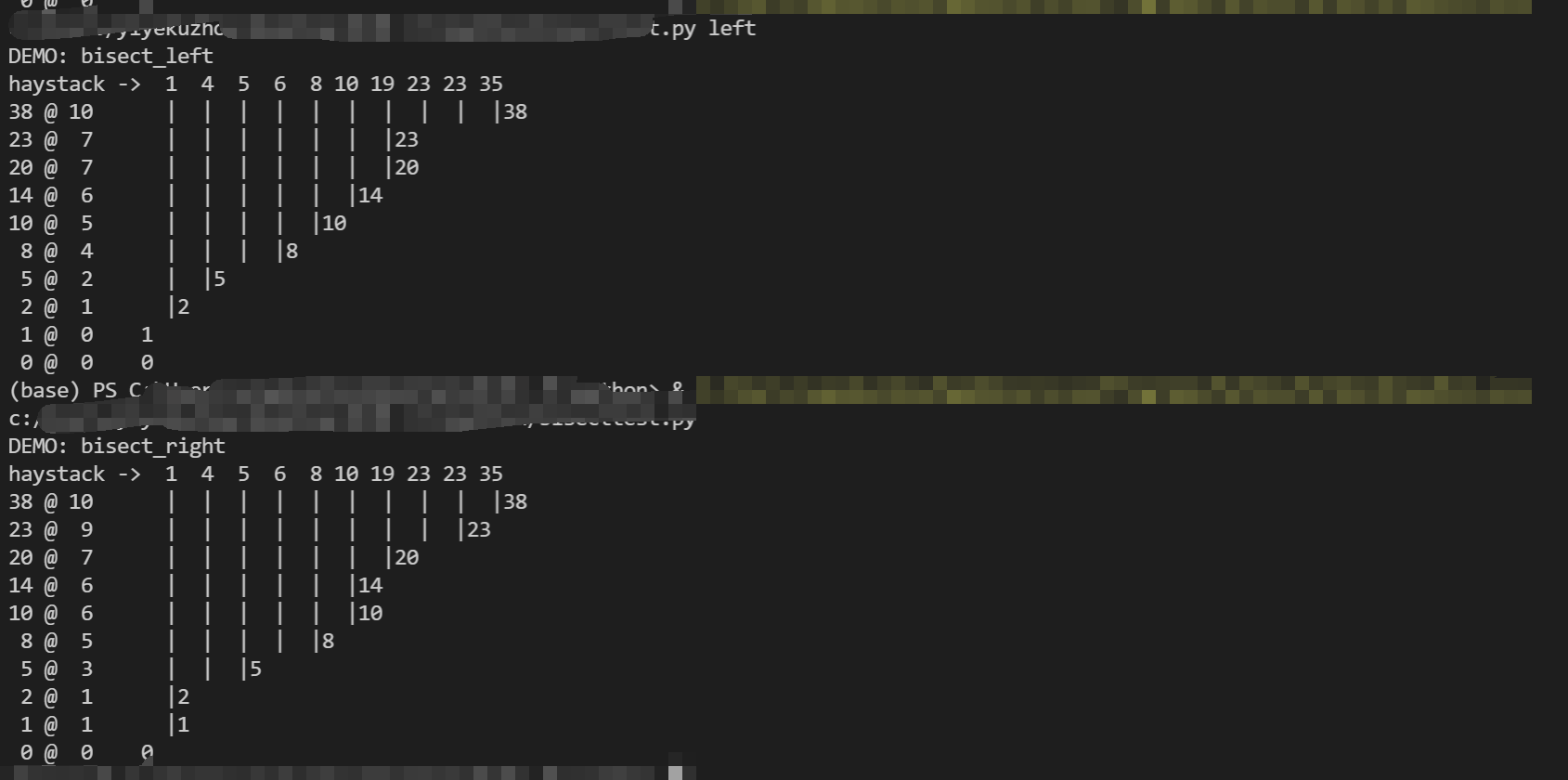
可以用来建立索引
1
2
3
4
5
6
7
8
9
| #根据一个分数查询成绩
def greae(score,breakpoints=[10,20,30,40,50],grades='abcdef'):
i = bisect.bisect(breakpoints,score)
print(grades[i])
return grades[i]
print([greae(score) for score in [11,13,55,44,33]])
#['b', 'b', 'f', 'e', 'd']
|
用bisect.insort插入新元素
**作用:**insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。
insort 跟 bisect 一样,有 lo 和 hi 两个可选参数用来控制查找的范围。它也有个变体叫 insort_left,这个变体在背后用的是 bisect_left。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| SIZE=7
random.seed(1729)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE*2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
'''
用了随机种子,所以必定是这个列表
10 -> [10]
0 -> [0, 10]
6 -> [0, 6, 10]
8 -> [0, 6, 8, 10]
7 -> [0, 6, 7, 8, 10]
2 -> [0, 2, 6, 7, 8, 10]
10 -> [0, 2, 6, 7, 8, 10, 10]
'''
|
2.9 列表不是首选时
2.9.1数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更 高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| from array import array
from random import random
floats = array('d',(random() for i in range(10**7)))
print (len(floats),floats[-1])
fp = open('floats.bin', 'wb')
floats.tofile(fp)
fp.close()
floats2 = array('d')
fp = open('floats.bin', 'rb')
floats2.fromfile(fp,10**7)
print(floats2[-1])
print(floats == floats)
fp.close()
'''
10000000 0.9887800460985485
0.9887800460985485
True
'''
|
说明array.tofile 和 array.fromfile 用于读取和写入二进制文件非常快
列表和数组的属性和方法:这个用了再参考吧
2.9.2 内存视图
memoryview 是一个内置类,它能让用户在不复制内容的情况下操作同 一个数组的不同切片。
例子:
试了试改书里的代码,我觉得这个更直观体现了
1.memoryview只取内存,不是重新生成的对象,可以修改其内容
2.memv_oct[7] = 0xc 把高位修改成了1100,所以值变成了3073
1
2
3
4
5
6
7
8
9
10
11
12
| numbers = array('h',[-2,-1,0,1,2])
memv = memoryview(numbers)
print (memv.tolist())
memv_oct = memv.cast('B')
print(memv_oct.tolist())
print(bin(memv[3]))
memv_oct[7] = 0xc
print(bin(3073))
print(bin(memv[3]))
print(numbers)
|
2.9.3 NumPy和SciPy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import numpy
a = numpy.arange(12)
print(a)
print(type(a))
print(a.shape)
a.shape = 3,4
print(a)
print(a[2])
print(a[2,1])
print(a[:,1])
print(a.transpose())
'''
<class 'numpy.ndarray'>
(12,)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[ 8 9 10 11]
9
[1 5 9]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
'''
|
2.9.4 双向队列和其他形式的队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
from collections import deque
dq = deque(range(10), maxlen=10)
print(dq)
dq.rotate(3)
print(dq)
dq.rotate(-4)
print(dq)
dq.appendleft(-1)
print(dq)
dq.appendleft(2)
print(dq)
dq.extend([11,22,33])
print(dq)
dq.extendleft([-1,-2,-3])
print(dq)
'''
双向队列实现了大部分列表所拥有的方法,也有一些额外的符合自身设
计的方法,比如说 popleft 和 rotate。但是为了实现这些方法,双向
队列也付出了一些代价,从队列中间删除元素的操作会慢一些,因为它
只对在头尾的操作进行了优化。
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序
中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
'''
|
除了 deque 之外,还有些其他的 Python 标准库也有对队列的实现。
queue 提供了同步(线程安全)类 Queue、LifoQueue 和 PriorityQueue,不同的线程可以利用这些数据类型来交换信息。这三 个类的构造方法都有一个可选参数 maxsize,它接收正整数作为输入 值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元 素来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程 移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃 线程的数量。
multiprocessing 这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给 进程间通信用的。同时还有一个专门的 multiprocessing.JoinableQueue 类型,可以让任务管理变得更方 便。
asyncio ,Python 3.4 新提供的包,里面有 Queue、LifoQueue、PriorityQueue 和 JoinableQueue,这些类受 到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务 管理提供了专门的便利。 heapq 跟上面三个模块不同的是,heapq 没有队列类,而是提供了 heappush 和 heappop 方法,让用户可以把可变序列当作堆队列或者优 先队列来使用。