python学习-3
第 3 章 字典和集合
3.1 泛映射类型
如果一个对象是可散列的,那么在这个对象的生命周期中,它 的散列值是不变的,而且这个对象需要实现 __hash__() 方 法。另外可散列对象还要有 __qe__() 方法,这样才能跟其他 键做比较。如果两个可散列对象是相等的,那么它们的散列值 一定是一样的……
字典的构造方法
1 | |
3.2 字典推导
可以像{k.upper():v for k,v in dict_t.items() if v<2}这样生成字典并且过滤需要的条件
1 | |
3.3 常见的映射方法
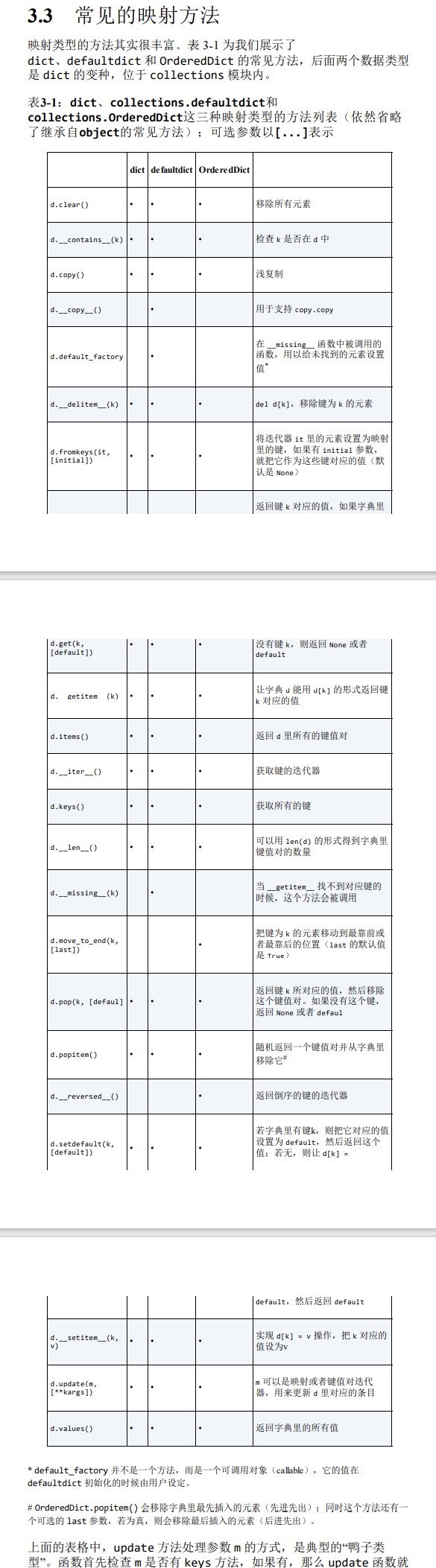
用setdefault处理找不到的键
如果字典找不到正确的键,则会抛出异常,这时候就需要一个找不到键的时候的默认返回值,第一种写法
1 | |
第二种写法:
1 | |
这2种写法虽然效果一样,但是第一种实际上查询了2次,如果键不存在的话还得再次查询,第二种就可一次完成操作
3.4 映射的弹性键查询
3.4.1 defaultdict:处理找不到的键的一个选择
我们新建了这样一个字典:dd = defaultdict(list),如果键 ‘new-key’ 在 dd 中还不存在的话,表达式 dd[‘new-key’] 会按照以 下的步骤来行事。
(1) 调用 list() 来建立一个新列表。
(2) 把这个新列表作为值,‘new-key’ 作为它的键,放到 dd 中。
(3) 返回这个列表的引用。
而这个用来生成默认值的可调用对象存放在名为 default_factory 的 实例属性里。
1 | |
如果在创建 defaultdict 的时候没有指定 default_factory,查询不 存在的键会触发 KeyError。
3.4.2 特殊方法__missing__
所有的映射类型在处理找不到的键的时候,都会牵扯到 __missing__ 方法。这也是这个方法称作“missing”的原因。虽然基类 dict 并没有定 义这个方法,但是 dict 是知道有这么个东西存在的。也就是说,如果 有一个类继承了 dict,然后这个继承类提供了 missing 方法,那 么在 __getitem__ 碰到找不到的键的时候,Python 就会自动调用它, 而不是抛出一个 KeyError 异常。
1 | |
isinstance(key, str) 测试在上面的 _missing_ 中是必需的。
如果没有这个测试,只要 str(k) 返回的是一个存在的键,那么 _missing_ 方法是没问题的,不管是字符串键还是非字符串键,它都能正常运行。但是如果 str(k) 不是一个存在的键,代码就会陷入无限递归。这是因为 _missing_ 的最后一行中的 self[str(key)] 会 调用 __getitem__,而这个 str(key) 又不存在,于是 _missing_ 又会被调用。 为了保持一致性,__contains__ 方法在这里也是必需的。这是因为 k in d 这个操作会调用它,但是我们从 dict 继承到的 __contains__ 方法不会在找不到键的时候调用 __missing__ 方法。__contains__ 里还有个细节,就是我们这里没有用更具 Python 风格的方式——k in my_dict——来检查键是否存在,因为那也会导致 __contains__ 被递 归调用。为了避免这一情况,这里采取了更显式的方法,直接在这个 self.keys() 里查询。
3.5 字典的变种
这一节总结了标准库里 collections 模块中,除了 defaultdict 之外 的不同映射类型。
collections.OrderedDict
这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致 的。OrderedDict 的 popitem 方法默认删除并返回的是字典里的最后 一个元素,但是如果像 my_odict.popitem(last=False) 这样调用 它,那么它删除并返回第一个被添加进去的元素。
collections.ChainMap
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时 候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个 功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射 对象来代表一个作用域的上下文。在 collections 文档介绍 ChainMap 对象的那一部分
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候 都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或 者是当成多重集来用——多重集合就是集合里的元素可以出现不止一 次。Counter 实现了 + 和 - 运算符用来合并记录,还有像 most_common([n]) 这类很有用的方法。most_common([n]) 会按照次 序返回映射里最常见的 n 个键和它们的计数,
1 | |
colllections.UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。 跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不 同,UserDict 是让用户继承写子类的。
3.6 子类化UserDict
就创造自定义映射类型来说,以 UserDict 为基类,总比以普通的 dict 为基类要来得方便。 这体现在,我们能够改进示例 3-7 中定义的 StrKeyDict0 类,使得所有的键都存储为字符串类型。 而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时 会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
UserDict 并不是 dict 的子类,但是 UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上 是 UserDict 最终存储数据的地方。这样做的好处是,比起上例 ,UserDict 的子类就能在实现 _setitem_ 的时候避免不必要的递归,也可以让 _contains_ 里的代码更简洁。 多亏了 UserDict,示例 3-8 里的 StrKeyDict 的代码比示例 3-7 里的 StrKeyDict0 要短一些,功能却更完善:它不但把所有的键都以字符串的形式存储,还能处理一些创建或者更新实例时包含非字符串类型的键这类意外情况。
self.data会把所有的key转换为字符串,所以这里__contains__方法里写return str(key) in self.data即可
1 | |
MutableMapping.update
这个方法不但可以为我们所直接利用,它还用在 __init__ 里,让 构造方法可以利用传入的各种参数(其他映射类型、元素是 (key, value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背 后是用 self[key] = value 来添加新值的,所以它其实是在使用我们 的 __setitem__ 方法。
Mapping.get
在 上一个示例中,我们不得不改写 get 方法,好让 它的表现跟 __getitem__ 一致。这个实例就没这个必要了,因为它继承了 Mapping.get 方法.
3.7 不可变映射类型
MappingProxyType
如果给这个类一个映射,它会返回一个只读的映 射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射 做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对 原映射做出修改。演示:
1 | |
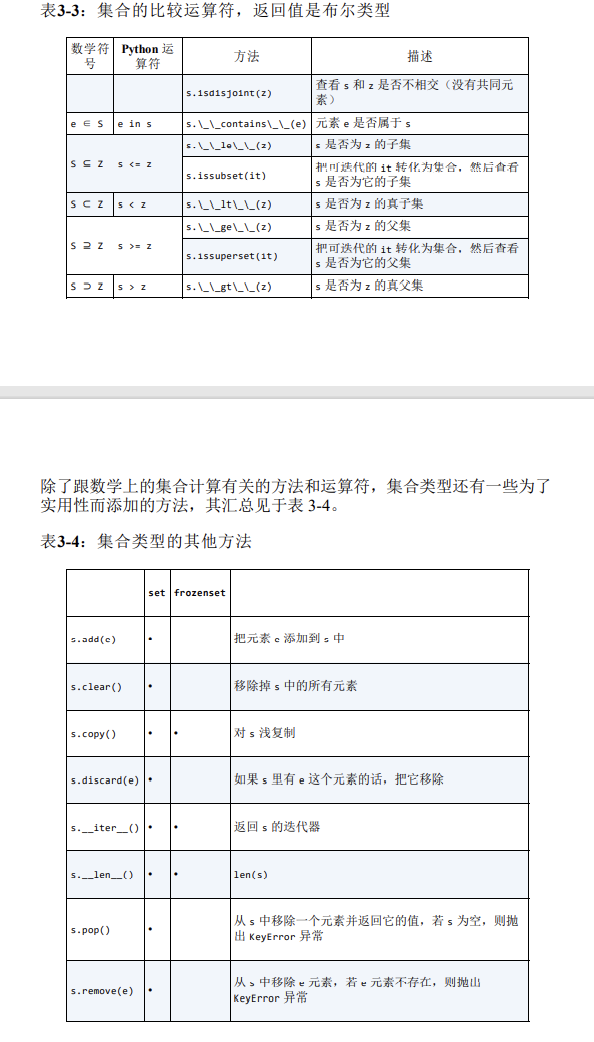
3.8 集合论
集合中的元素必须是可散列的,set 类型本身是不可散列的,但是 frozenset 可以。因此可以创建一个包含不同 frozenset 的 set。 除了保证唯一性,集合还实现了很多基础的中缀运算符。
给定两个集合 a 和 b,a | b 返回的是它们的合集,a & b 得到的是交集,而 a - b 得到的是差集。行时间。
例如想求集合a在b中的出现次数
1 | |
needles 的元素在 haystack 里出现的次数,以下代码可以用在任何可迭代对象上
1 | |
3.8.1 集合字面量
除空集之外,集合的字面量——{1}、{1, 2},等等——看起来跟它的 数学形式一模一样。如果是空集,那么必须写成 set() 的形式。
1 | |
3.8.2 集合推导
1 | |
3.8.3 集合的操作

3.9 dict和set的背后
3.9.2 字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。 在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。 在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两 个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大 小一致,所以可以通过偏移量来读取某个表元。 因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达 到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。 如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。
01 散列值和相等性
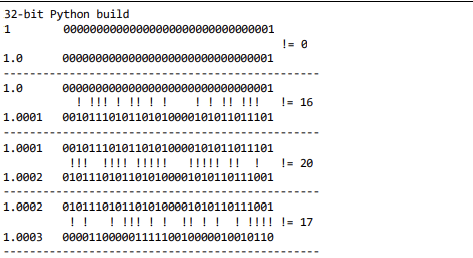
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义 对象调用 hash() 的话,实际上运行的是自定义的 __hash__。如 果两个对象在比较的时候是相等的,那它们的散列值必须相等,否 则散列表就不能正常运行了。例如,如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型 和浮点)的内部结构是完全不一样的。 为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间 中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等 的对象,它们散列值的差别应该越大。示例 3-16 是一段代码输 出,这段代码被用来比较散列值的二进制表达的不同。注意其中 1 和 1.0 的散列值是相同的,而 1.0001、1.0002 和 1.0003 的散列值则 非常不同。
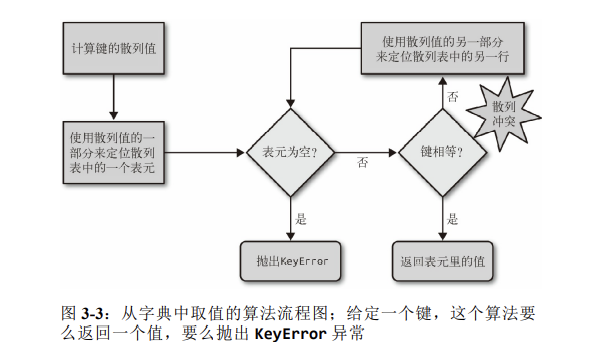
02. 散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算 search_key 的散列值,把这个值最低 的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看 当前散列表的大小)。若找到的表元是空的,则抛出 KeyError 异 常。若不是空的,则表元里会有一对 found_key:found_value。 这时候 Python 会检验 search_key == found_key 是否为真,如 果它们相等的话,就会返回 found_value。 如果 search_key 和 found_key 不匹配的话,这种情况称为散列 冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映 射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字 的一部分。为了解决散列冲突,算法会在散列值中另外再取几位, 然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表 元。 若这次找到的表元是空的,则同样抛出 KeyError;若非 空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复 以上的步骤。
具体步骤如图
3.9.3 dict的实现及其导致的结果
-
键必须是可散列的 一个可散列的对象必须满足以下要求。
(1) 支持 hash() 函数,并且通过
__hash__()方法所得到的散列 值是不变的。(2) 支持通过 eq() 方法来检测相等性。
(3) 若 a == b 为真,则 hash(a) == hash(b) 也为真。 所有由用户自定义的对象默认都是可散列的,因为它们的散列值由 id() 来获取,而且它们都是不相等的。
-
字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下 -
键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开 销,但它们提供了无视数据量大小的快速访问——只要字典能被装 在内存里。
-
键的次序取决于添加顺序
键有顺序,并且取决于添加顺序,判断2个字典是否一样时只看里面存储的数据
1 | |
3.9.4 set的实现以及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用**(就像在字典里只存放键而没有相应的值)。**在 set 加 入到 Python 之前,我们都是把字典加上无意义的值当作集合来用的。字典和散列表的几个特点,对集合来说几乎都是适用的。为了避免太多重复的内容,这些特点总结如下。
集合里的元素必须是可散列的。
集合很消耗内存。
可以很高效地判断元素是否存在于某个集合。
元素的次序取决于被添加到集合里的次序。
往集合里添加元素,可能会改变集合里已有元素的次序
和字典的特点几乎差不多
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!,本博客仅用于交流学习,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 文章作者拥有对此站文章的修改和解释权。如欲转载此站文章,需取得作者同意,且必须保证此文章的完整性,包括版权声明等全部内容。未经文章作者允许,不得任意修改或者增减此文章内容,不得以任何方式将其用于商业目的。若造成严重后果,本人将依法追究法律责任。 阅读本站文章则默认遵守此规则。